TLDR: chatcraft.org is now smooth as butter and maximally performant thanks to throttling LLM chat-completion rendering via requestAnimationFrame().
Showing incremental responses from LLMs helps work around the fact that LLMs are slow. However there is always tradeoff between incremental progress indicators and throughput… In this case this trade-off was ridiculously amplified by performance architecture in web browser engines.
Groq is so fast… that it made chatcraft.org slow
Recently I added groq as a free, login-less backend to https://chatcraft.org. Then a friend reported a really curious bug where chatcraft would hang his Firefox during LLM responses.
Primed by above bugreport, I started to notice that in some cases during LLM inference, chatcraft UI stops responding for upwards of a minute in chrome too. I started to realize that where I was intuitively [and wrongly] attributing janky LLM text completions to LLM providers and crappy internet, I as a developer was at fault. After spending a good chunk of my life on web performance at Mozilla, this knowledge was unbearable.
Analysis
I fired up devtools to get a trace:
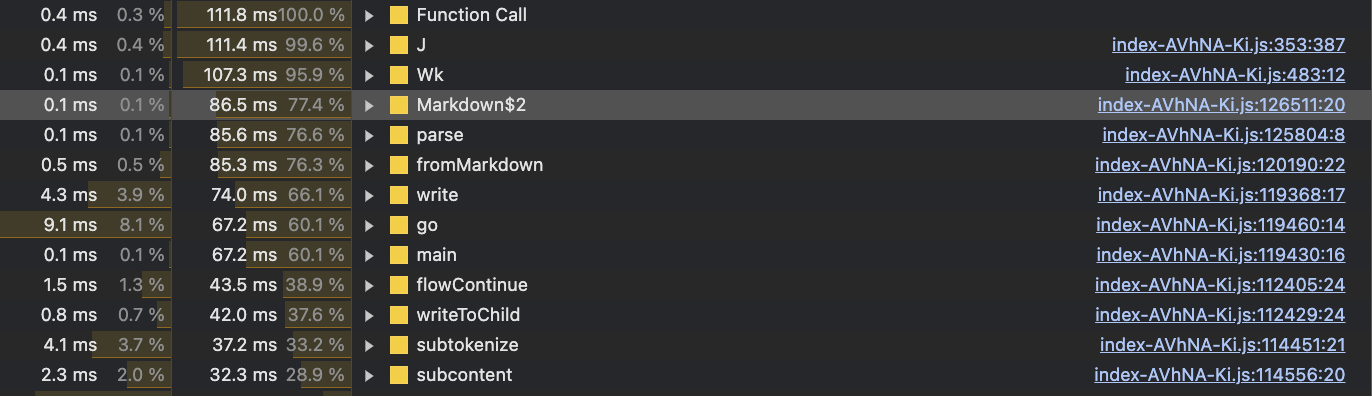
LLMs like to speak markdown, but parsing markdown and re-rendering it as HTML is expensive as hell.
I have no idea how to get the Chrome devtools to surface the true cause of this:
Updating the DOM tends to cause reflows, which are thread-blocking operations that compute the layout of the webpage. Delayed painting is a further optimization to reduce layout thrashing and increase rendering throughput. Off-main-thread animations are a hack to make the webpage look responsive during this process, even though it may be unable to respond to any user interaction.
We cause a lot of DOM updates by re-rendering markdown HTML on every token.
(I also have no idea how to unminify symbols in browser project to make perf tracing easier, if anyone knows, I would appreciate a chatcraft pull request).
I had David help me narrow down where in the code to start fixing this.
Fix
Final solution was to buffer responses from LLM providers until requestAnimationFrame() indicates that the layout engine is ready to render. Whereas previously we were forcing expensive JS calculations + DOM updates on every token from LLMs (causing the poor single-threaded-with-hacks browser to repeat a lot of work), now we adapt to the speed of the underlying browser.
sequenceDiagram
participant LLM as LLM Event Stream
participant Buffer as Chatcraft Receive Loop
participant Browser as Browser Layout Engine
LLM->>Buffer: Generate token
Buffer->>Buffer: Accumulate tokens
Buffer->>Browser: requestAnimationFrame()
Browser->>Buffer: requestAnimationFrame callback: Ready to render
Buffer->>Browser: Release accumulated tokens
Browser->>Browser: Render markdown as DOM, Reflows, Painting
Measurements
End result on my ridiculously overpowered M3 Max laptop:
- Browser can render roughly every 3 tokens with gpt-4o
- llama-70b on groq can render every 45-60 tokens
- groq llama-8b can render every ~120 tokens
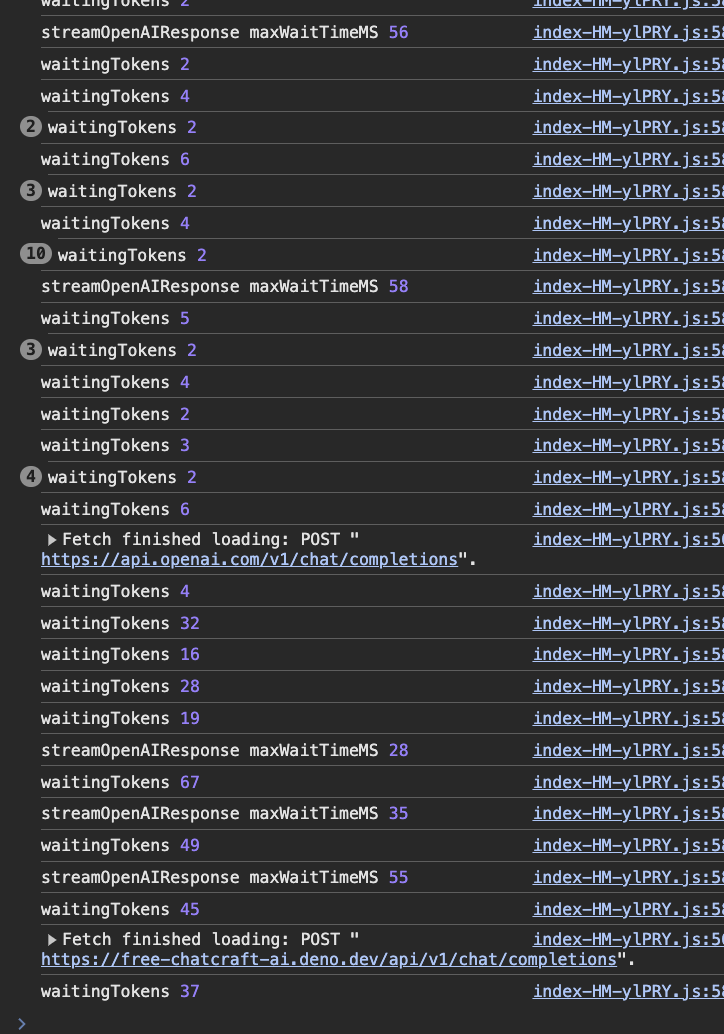
The results are even more dramatic on my underpowered Android tablet. There the browser engine does about 2 updates before groq is done responding. (Previously I could ask a question, then put the tablet away for a few minutes while waiting for a response). It’s so embarassing that this was completely self-inflicted :)