I needed a way to do some programming while offline. These days I feel very unproductive without https://chatcraft.org (the best chat UI for programming) and a good LLM to chat with about coding.
Chatcraft needed a few small fixes to enable llama.cpp support. Here’s how to run models with llama.cpp with chatcraft.org without internet:
Instructions
Install and run llama.cpp. Follow https://github.com/ggerganov/llama.cpp instructions for your platform.
For mac:
# install llama.cpp
brew install llama.cpp
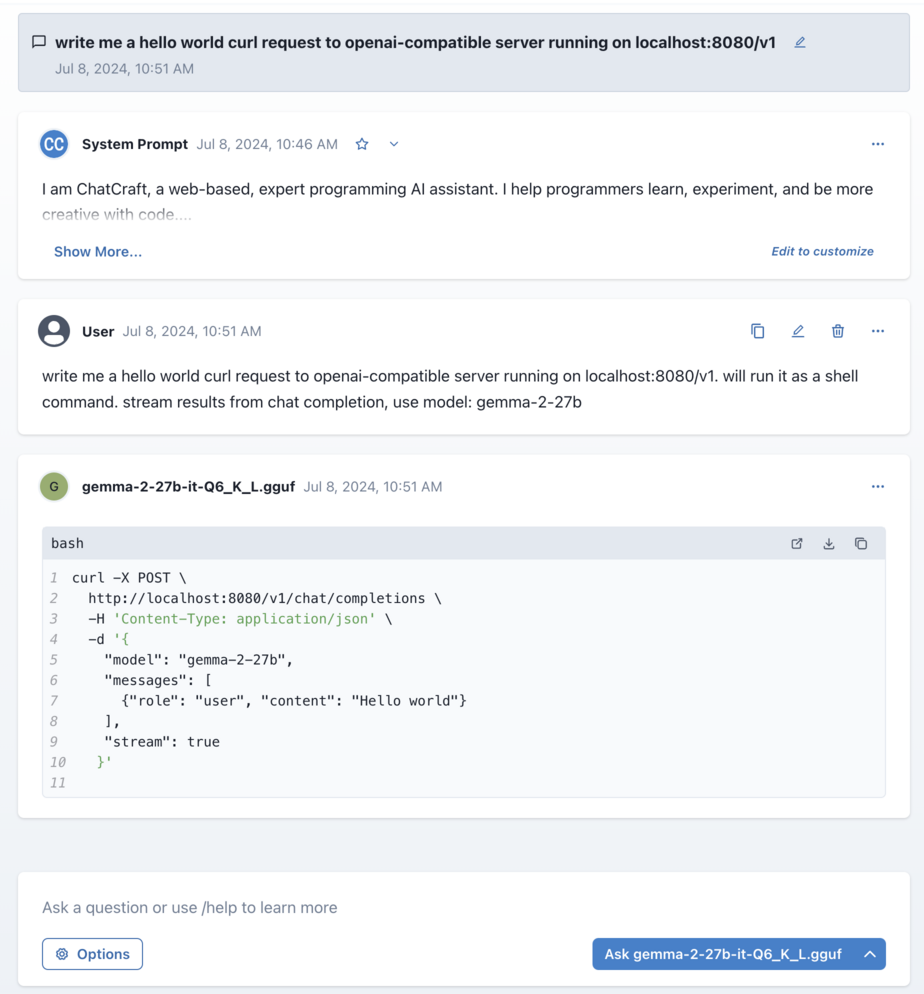
# start llama.cpp server & auto-download a good small (~6GB) model
llama-server --hf-repo "bartowski/Llama-3-Instruct-8B-SPPO-Iter3-GGUF" --hf-file Llama-3-Instruct-8B-SPPO-Iter3-Q6_K.gguf
# For more advanced usage I recommend gemma 27b: the smallest smarter-than-gpt-3.5 model (~21GB)
# llama-server --hf-repo bartowski/gemma-2-27b-it-GGUF --hf-file gemma-2-27b-it-Q6_K_L.gguf
Setup local chatcraft dev env by following the instructions in the chatcraft repo
git clone https://github.com/tarasglek/chatcraft.org/
cd chatcraft.org
pnpm install
pnpm dev
^ will output a development url like http://localhost:5173/, open it.
Go to chatcraft settings and add http://localhost:8080/v1 to api providers. Enter a dummy api key.
Enjoy!